
Tokens
In my last post, I talked about using Regex to match the pattern of a WeekDay or ClockTime string and unpacking this into a meaningful object. This is known as Parsing, and we can see plenty of examples in the .Net framework, int.Parse(), Guid.Parse(), plus others. But how do we deal with parsing more complicated bodies of text that are made up of multiple words / parts?
"Monday 08:30am"
"tue 18:30"
"thurs 12:30pm"
We’re going to tackle this in two phases firstly we’re going to split our text into parts and parse them into tokens (Tokenisation/Scanning phase), then we’re going to check the tokens match a correct syntax pattern and turn that into an object (Parsing phase).
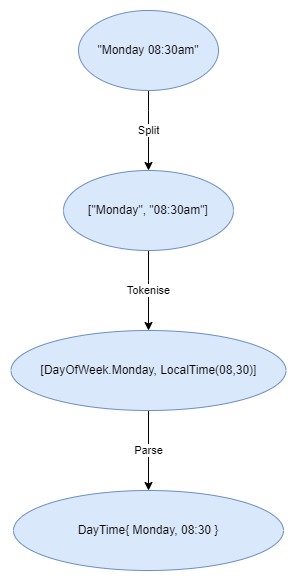
Tokeniser
To start with, we’re going to need a Tokeniser for converting a complete string into tokens. This is going to need a split pattern and a number of ITokenParsers to identify and convert the individual string fragments into sentence primitives.
public class Tokeniser
{
Regex _splitPattern;
IList<ITokenParser> _tokenisers;
public Tokeniser(string splitPattern, params ITokenParser[] tokenisers)
{
_splitPattern = new Regex(splitPattern);
_tokenisers = tokenisers.ToList();
}
public IEnumerable<Token> Tokenise(string inputString)
{
var parts = _splitPattern.Split(inputString);
foreach (var part in parts)
{
var match = _tokenisers
.Select(t => t.Tokenise(part))
.Where(t => t.Successful)
.FirstOrDefault();
yield return match == null ?
Token.Create(part) :
match.Token;
}
}
}
public interface ITokenParser
{
TokenisationResult Tokenise(string token);
}
public class TokenisationResult
{
public Token Token { get; init; }
public bool Successful { get; init; }
}
We will now need to port the logic from the original post for matching and parsing DayOfWeek and LocalTime and implement our ITokenParser interface, then drop them all into the Tokeniser…
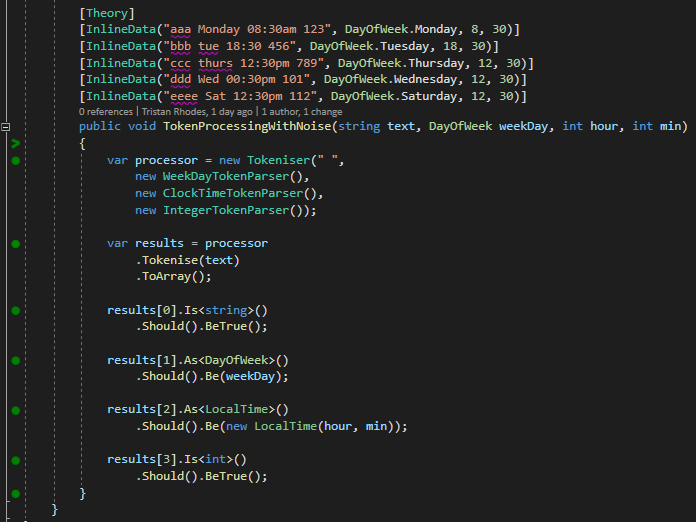
Now we have an array of Tokens generated from a string, with tokens that match a specific Tokeniser rule being captured and converted, note that I’ve also included an integer converter, and any unmatched tokens are returned as String tokens. But we still need something that checks if these tokens are a recognizable configuration, and then converts this into a meaningful object.
“Parsing” a complete DayTime
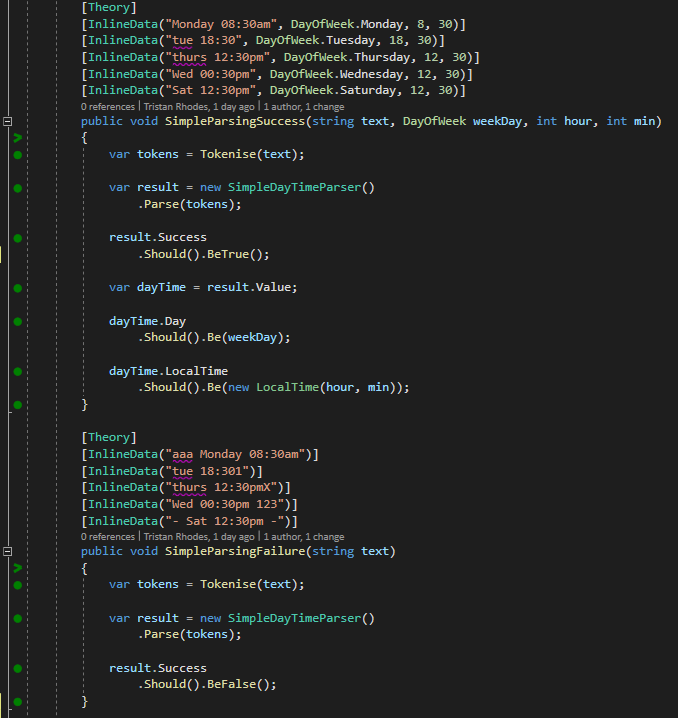
While we’re only writing one parser for one pattern right now, it’s a common concept, so we can start with an interface. We’ll also follow the Regex response pattern, which returns a Match object with a Success flag and result information, but we will be returning a typed object.
public interface IParser<T>
{
ParseResult<T> Parse(Token[] tokens);
}
public class ParseResult<T>
{
public bool Success { get; init; }
public T Value { get; init; }
}
Our DayTime object is composed of two parts, the Day and the Time. All we need now is to create a simple expression parser that takes an array of Token[] and populates the fields in a DayTime object.
public class DayTime
{
public DayTime(DayOfWeek day, LocalTime time)
{
Day = day;
LocalTime = time;
}
public DayOfWeek Day { get; }
public LocalTime LocalTime { get; }
}
public class SimpleDayTimeParser : IParser<DayTime>
{
public ParseResult<DayTime> Parse(Token[] tokens)
{
if (tokens.Length != 2)
return ParseResult<DayTime>.Failure();
if (!tokens[0].Is<DayOfWeek>())
return ParseResult<DayTime>.Failure();
if (!tokens[1].Is<LocalTime>())
return ParseResult<DayTime>.Failure();
var result = new DayTime(
tokens[0].As<DayOfWeek>(),
tokens[1].As<LocalTime>());
return ParseResult<DayTime>
.Successful(result);
}
}
And that’s it, we can convert our two part string into a higher order object.
Expression Trees and Parsers
Our “parser” implementation is a bit of an overstatement here, this is the most naive logic we can get. It doesn’t have any flexibility for supporting more complex structures and is only going to support a very explicit match. If we wanted to extend this to support more complex patterns, we’re going to be quite limited. Consider trying to solve the following patterns:
// Separate two part element context
"Pickup Mon 08:00 dropoff wed 17:00"
// Range elements with different separators
"Open Mon to Fri 08:00 - 18:00"
// Repeating tokens
"Tours 10:00 12:00 14:00 17:00 20:00"
// Repeating complex elements
"Events Tuesday 18:00 Wednesday 15:00 Friday 12:00"
To solve these problems, we’re going to need a parser with the ability to process an expression tree, and we’ll get to that next.
All the code is available in a small sandbox project I’m building to go along with a couple of posts here.
Note
Post updated 7th January to line up with work done on demo project.
