Regex
Because I went through a phase of being monumentally dumb recently, I felt it was appropriate to perform some kind of penance, and prove that I’m not actually an idiot when it comes to using Regex.
So this is an introductory post on using regex to perform basic tokenisation on a couple of common concepts, weekdays and clock times.
Regex for a Weekday
Let’s say we want to figure out if a string of characters represents the day Monday. Well, we need to figure out all the ways we can define Monday, then define that in a pattern. Mon, mon, Monday, monday are the 4 we’ll use to start. So, how do we create a pattern to find that?
Firstly, we’ll note that we want the beginning and the end of the string to line up with the beginning and the end of the word. To do this, we’ll need to use Anchors. These ensure that the text being matched begins at the beginning, and ends at the end of a string.
- ^ => This symbol anchors the beginning of a string
- $ => This symbol anchors the end of a string
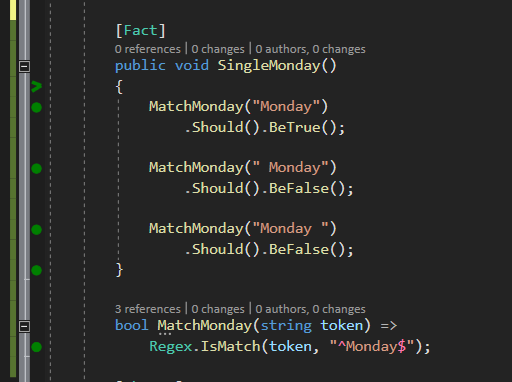
Then we need the word itself. Let’s start with a single literal text - Monday.
^Monday$
This will match the start and end of a string matching the phrase ‘Monday’. ‘ Monday’ and ‘Monday ‘ would not match.
But what about our other permutations?
Well, we can handle the casing at the beginning of the word by using a range of characters.
- [Mm] => this represents a match against either an upper case M or a lower case m, so we can add this to the beginning.
^[Mm]onday$
This gets us Monday and monday, but we have no abbreviation. So we need to add something to indicate that the last section is optional.
- ()? => wrapping braces and placing a question mark after an expression (or a single character) makes it optional, so we can add this to indicate that the suffix (day)? may or may not exist.
^[Mm]on(day)?$
Broken down it looks like this:

And that’s it, we’ve got a nice little regex expression to check for Monday in various forms.
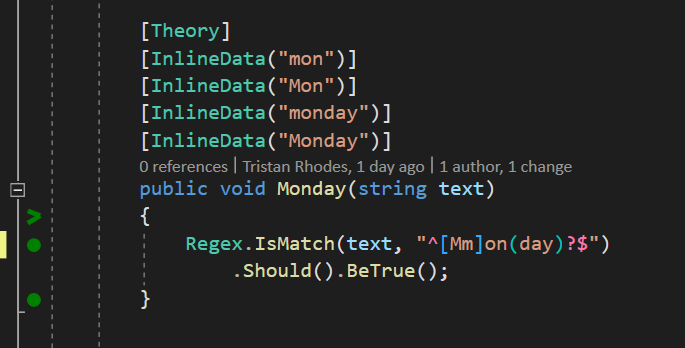
You can see the whole test suite here.
Groups
Many versions of regex have the ability to retrieve named groups from captures, in the .Net Regex library, this is achieved by wrapping the target in (?<name>pattern), and when you retrieve the result of a Regex.Match(), you will be able to look in the Match.Groups[“name”] property to retrieve the value.
- (?<name>pattern) => Capture a named group where the pattern is met.
This is useful when we have a number of related patterns that we want to group together, we can use the group names, combined with the | operator, which functions as an OR condition.
- this|that => match “this” or “that”
Full Week Regex
Now if we take all the regex for the individual days of the week, we can use the regex Group syntax (?<dayName>dayPattern), combined with the or pipe |. This enables us to set up a named match that covers each day, and when that match is met, we return the named group for the match.
”^(?<Monday>[Mm]on(day)?)|(?<Tuesday>[Tt]ue(sday)?)|(?<Wednesday>[Ww]ed(nesday)?)|(?<Thursday>[Tt]hu(rs(day)?)?)|(?<Friday>[Ff]ri(day)?)|(?<Saturday>[Ss]at(urday)?)|(?<Sunday>[Ss]un(day)?)$”
With this regex, we can now validate a string token and convert it from a range of input values to the correct matching Enum using some basic mapping logic.
DayOfWeek? Convert(string token)
{
var match = Regex.Match(token, FullWeekRegex);
if (!match.Success)
throw new NotSupportedException($"Bad Format: {token}");
if (match.Groups["Monday"].Success)
return DayOfWeek.Monday;
if (match.Groups["Tuesday"].Success)
return DayOfWeek.Tuesday;
if (match.Groups["Wednesday"].Success)
return DayOfWeek.Wednesday;
if (match.Groups["Thursday"].Success)
return DayOfWeek.Thursday;
if (match.Groups["Friday"].Success)
return DayOfWeek.Friday;
if (match.Groups["Saturday"].Success)
return DayOfWeek.Saturday;
if (match.Groups["Sunday"].Success)
return DayOfWeek.Sunday;
throw new NotSupportedException($"Bad Format: {token}");
}
Now we can run our word through this text converter and get back an Enum for DayOfWeek. This process is known as Tokenisation and is the first step in building a text processing system.
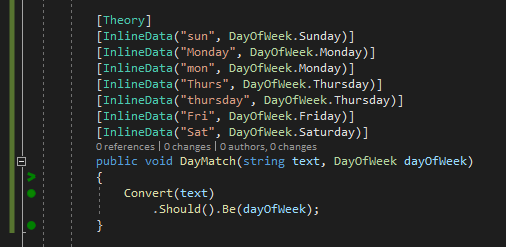
The whole setup is available here.
Clock Time
Let’s have a look at doing the same with a clock time. What’s the anatomy?
- Starts with 1-2 digits to indicate the hour part.
- Colon character ‘:’ to separate the hour from the minute.
- 2 digits to indicate the minute part.
- An optional am/pm indicator which, if omitted indicates a 24 hour clock.
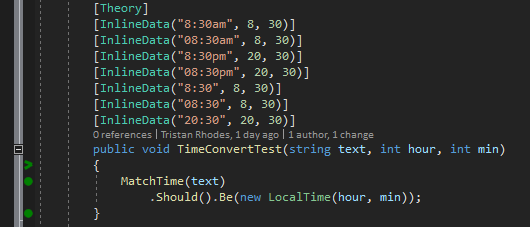
Based on this, we’re going to need to match the following patterns:
// 12 Hr
"8:30am"
"08:30am"
"8:30pm"
"08:30pm"
// 24 Hr
"20:30"
"10:30"
"1:30"
So what does the pattern look like?

This gives us a pattern match, so we can detect a time pattern (at least approximately), but we still need to convert it into something useful, so we have to pick it apart. To do this, we’re going to go back to groups.
^(?<hr>\d{1,2}):(?<min>\d{2})((?<am>am)|(?<pm>pm))?$
Here we pull apart our clock time string and take the hour digits, the minute digits and the am/pm indicator group. Then we convert that into local time with a sprinkling of number range validation, and we’re done.
public LocalTime? MatchTime(string token)
{
var match = Regex.Match(token, @"^(?<hr>\d{1,2}):(?<min>\d{2})((?<am>am)|(?<pm>pm))?$");
if (!match.Success)
throw new NotSupportedException($"Bad Format: {token}");
var hour = int.Parse(match.Groups["hr"].Value);
var min = int.Parse(match.Groups["min"].Value);
var am = match.Groups["am"].Success;
var pm = match.Groups["pm"].Success;
var twentyFourHr = !am && !pm;
if (min > 60)
throw new NotSupportedException($"Bad Format: {token}");
if (twentyFourHr && hour < 24)
{
return new LocalTime(hour, min);
}
else if (am && hour < 12)
{
return new LocalTime(hour, min);
}
else if (pm && hour < 12)
{
return new LocalTime(hour + 12, min);
}
throw new NotSupportedException($"Bad Format: {token}");
}
And we can see that running against our range of formats here:
Now we have the logic to determine if a string matches a Weekday or ClockTime pattern, and return the appropriate typed object we’ve got the first steps of a system to tokenise strings. I’ve spun up a small repo to play with these concepts, it’s available here, and I’m going to use it as a sandbox to dive further into the really cool powerful things you can do with regex and tokens.
If you want to pull the repo and have a play, there are a couple of exercises you can do:
- Can you make the day converter process say, German/French as well as English interpretations of days?
- What other international clock formats are there? Can you add support them?
- Create a basic tokeniser for an enum representing Hotel Room types, or Retail Stores.
