
Brief
This post is part of a series that covers the concept of resilience in a distributed environment, and how to improve a systems handling of transient errors.
Posts
- Part 1 - System failure and Resilience
- Part 2 - Implementing Resilience
- Part 3 - Benefits of Resilience
So what benefit does the scenario give us? How does this affect our systems, load and logging? Why is it worth doing?
I put together a small application to demo the scenarios discussed in the previous posts. It’s a glorious piece of UI design, as you can see below:
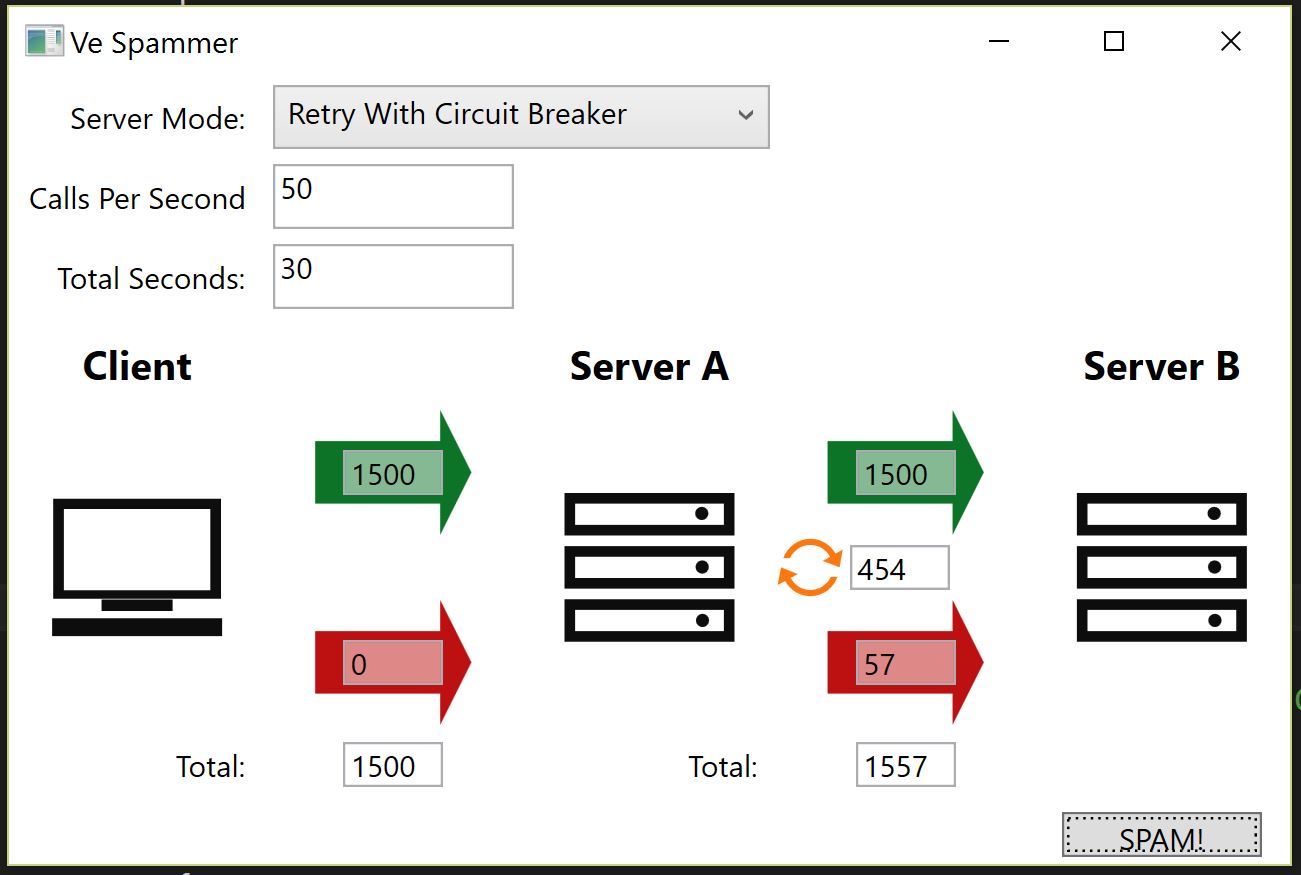
We are interested in how robust the connectivity is between layers. The green arrows represent successful service calls, the red arrows represent failed calls. On the server side, the yellow refresh symbol indicates the number of calls that failed and were retried.
In the sample app we are running a service that will be unavailable 50% of the time, toggling on / off every 4 seconds. We are running requests at a rate of 50 per second, for 30 seconds, a total of 1500 requests.
The Server Mode field has the options:
- Raw - No resilience implementation, straight calls Client -> Server A -> Server B
- Retry - Calls from Server A -> Server B are retried up to 5 times, with a 1 second wait between each attempt.
- Retry With Circuit Breaker - This is the same as Retry but with a Circuit Breaker underneath which disabled further requests for 0.5 seconds when two calls fail in a row.
With this set up, we can now test the various scenarios and see exactly what kind of effect the different approaches have.
Raw
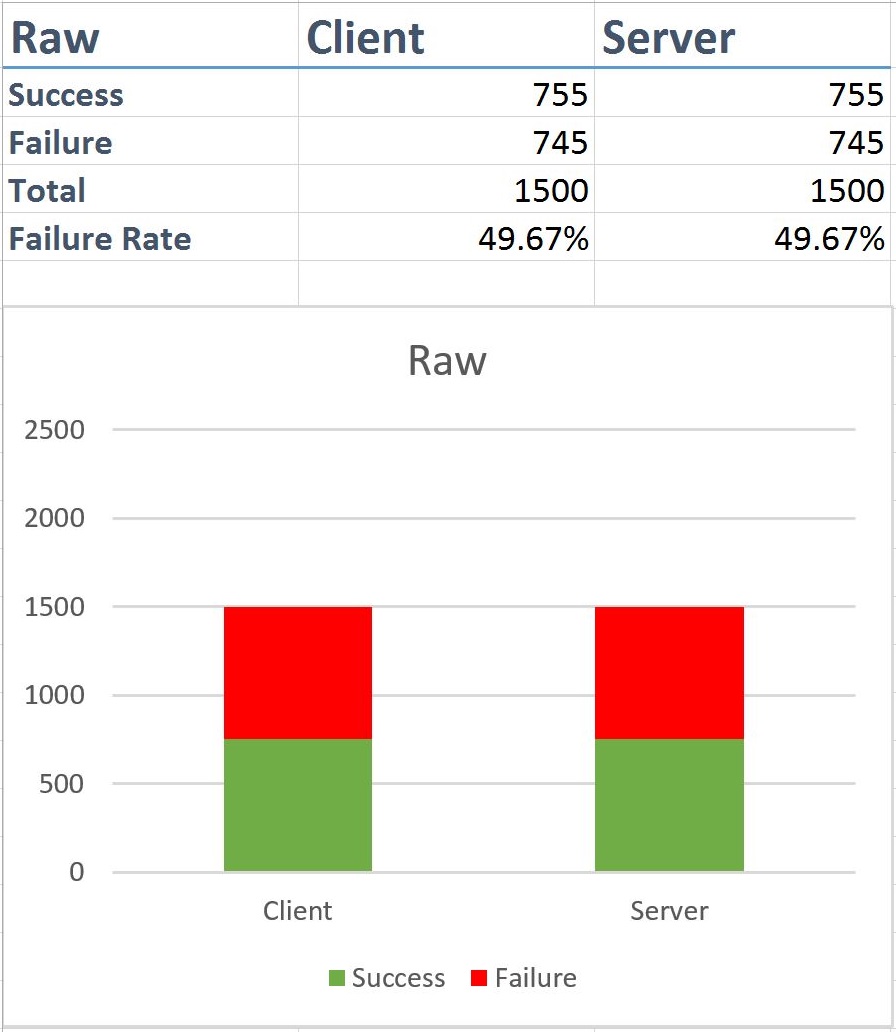
As you can see from this, any call from Client -> Server A will fail when the call from Server A -> Server B. This is essentially the worst case scenario for a system. In the case of the test application, we have around a 50% failure rate of client calls.
Retry
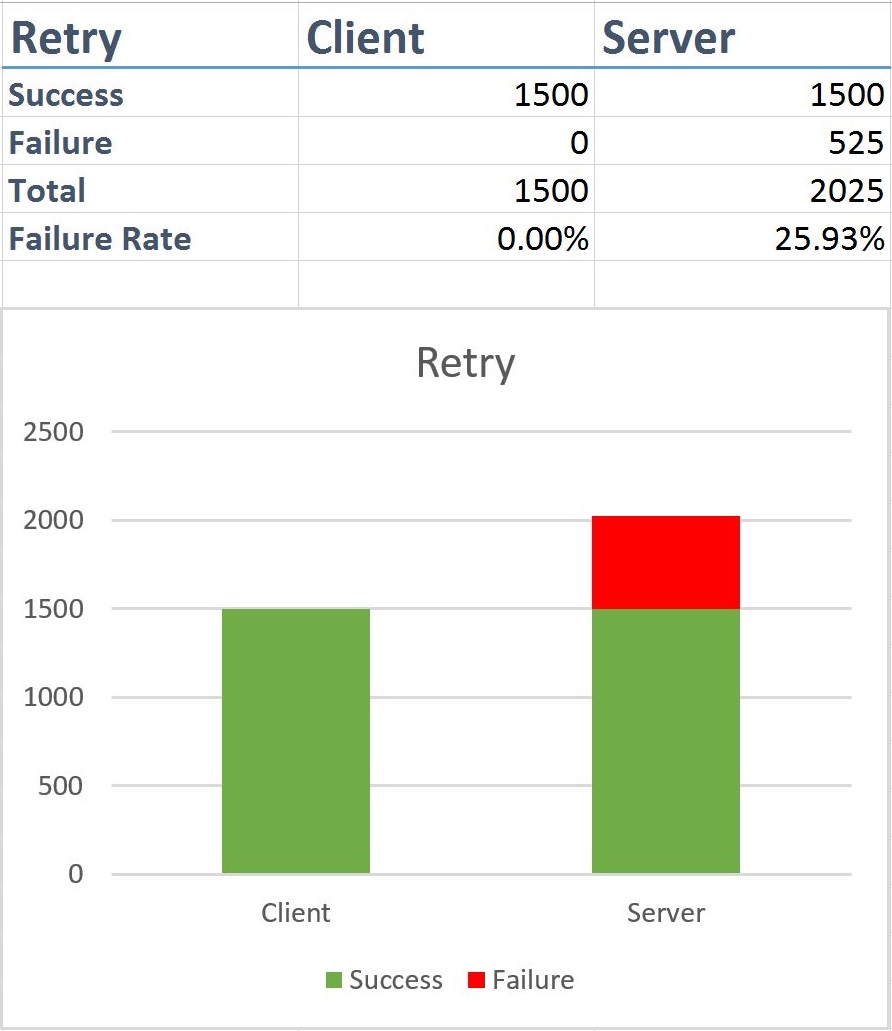
There’s a significant improvement just by applying a retry policy. There are now no failed client calls, but as you can see from the diagram, the number of failed calls between Server A and Server B has jumped, and has a 25% failure rate.
This will lead to unescessary noise in the system, lots of packets being sent that will fail, many failed requests, an increase in counters, and notifications being raised by monitoring software.
Retry with Circuit Breaker
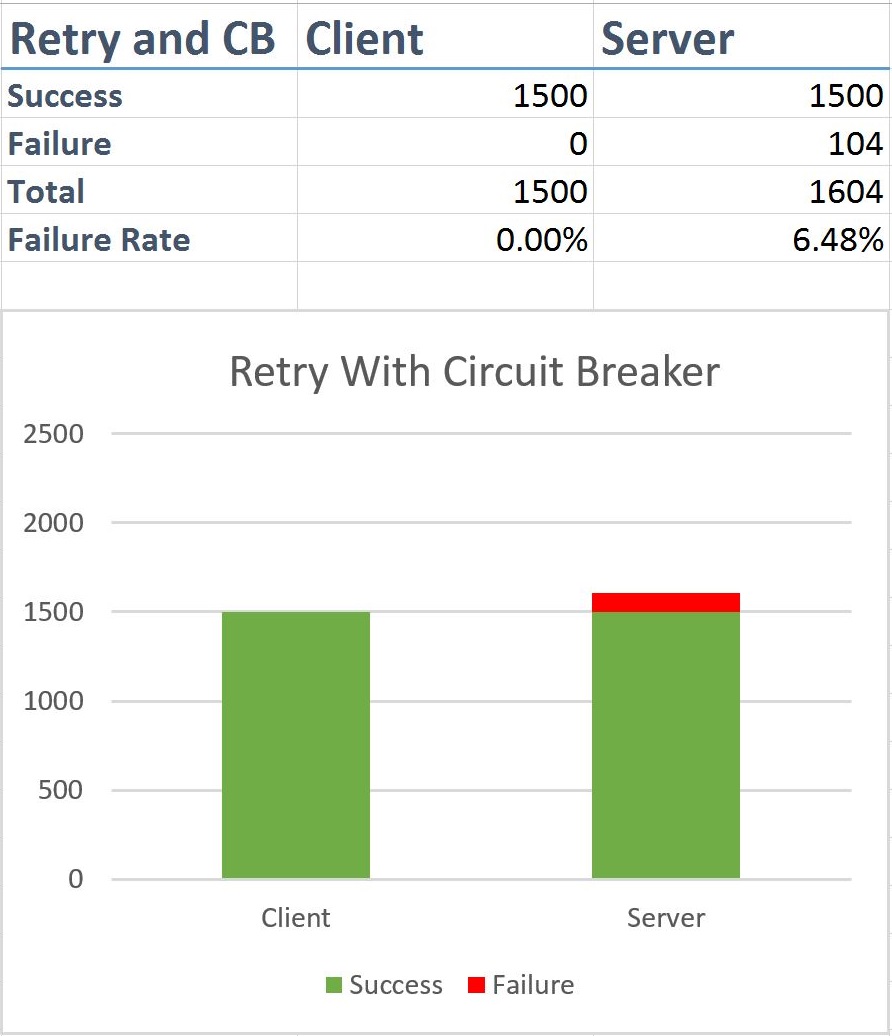
Finally, with the added circuit breaker, we can drop the failure rate between Server A and Server B to ~6.5%. This is a massive improvement. Considering we have made 1500 calls, between the client and Server A, and Server B is only available 50% of the time, we only made 104 failed calls, this is a huge improvement in network noise, while maintining availability for the client.
Conclusion
As you can see, resilience techniques can improve the experience for both the calling client, as well as reducing the load on the underlying system.
While this is a contrived example running in a local application, the concepts apply to larger distributed applications as well. As a company commits to a higher SLA, these techniques become critical, and once implemented the configuration of the retry and circuit breaker mechanisms will become a mathematical modeling problem, which is where those smart maths PHD people come in.
About the Application
The application is written in WPF, and makes heavy use of the TPL to run concurrent requests and Reactive Extensions to handle the stream of events generated by parallel tasks, with the retry mechanism using Polly. It is available for download from our public GitHub repo.
